- Published on
上下文工程:从提示工程到智能体时代的关键技术
- Authors

- Name
- Shoukai Huang

洞见(Photo by mohammad takhsh on Unsplash)
1. 上下文工程的提出与演进
随着大语言模型(LLM)技术的飞速发展,人工智能领域的关注点正从"提示工程"(Prompt Engineering)转向更为系统和动态的"上下文工程"(Context Engineering)。这一转变不仅仅是术语的变化,更代表了AI应用开发范式的根本性升级。
在智能体(Agent)时代,决定智能体成败的关键在于你赋予它的上下文的质量。正如Andrej Karpathy所言,LLM就像一种新型的操作系统,模型本身如同CPU,而上下文窗口则如同RAM,代表着模型的"工作内存"。
大多数智能体失败不再是模型失败,而是上下文失败。
1.1 上下文工程的定义与特征
"上下文工程"是一门设计和构建动态系统的学科,它以正确的格式在正确的时间提供正确的信息和工具,为大语言模型提供完成任务所需的一切。与"提示工程"侧重于单一字符串的指令不同,上下文工程关注的是系统性、动态性、精准性和信息格式。
- 系统性:上下文不仅仅是静态的提示模板,而是主LLM调用前由系统动态生成的输出。
- 动态性:上下文根据当前任务实时定制,可能包括日历、邮件、检索结果等。
- 精准性:核心在于确保模型不遗漏关键细节,避免"垃圾进,垃圾出"。
- 格式重要性:信息呈现方式至关重要,简洁摘要优于原始数据堆砌,结构化工具定义优于模糊说明。
1.2 上下文工程与提示工程的区别
"提示工程"强调如何编写精确的prompt,引导模型输出期望结果。但随着应用复杂度提升,单靠静态prompt已无法满足需求。上下文工程则要求开发者构建完整的信息环境,使模型在正确的时间获取正确的信息,做出最优决策。
LLM本质上是无状态函数,将输入转化为输出。要获得最佳输出,必须为其提供最佳输入——这正是上下文工程的核心。
2. 上下文的组成要素与类型
要理解上下文工程,需扩展"上下文"的定义。上下文不仅是你发给LLM的那一个问题,而是模型在生成答案前所看到的一切信息。
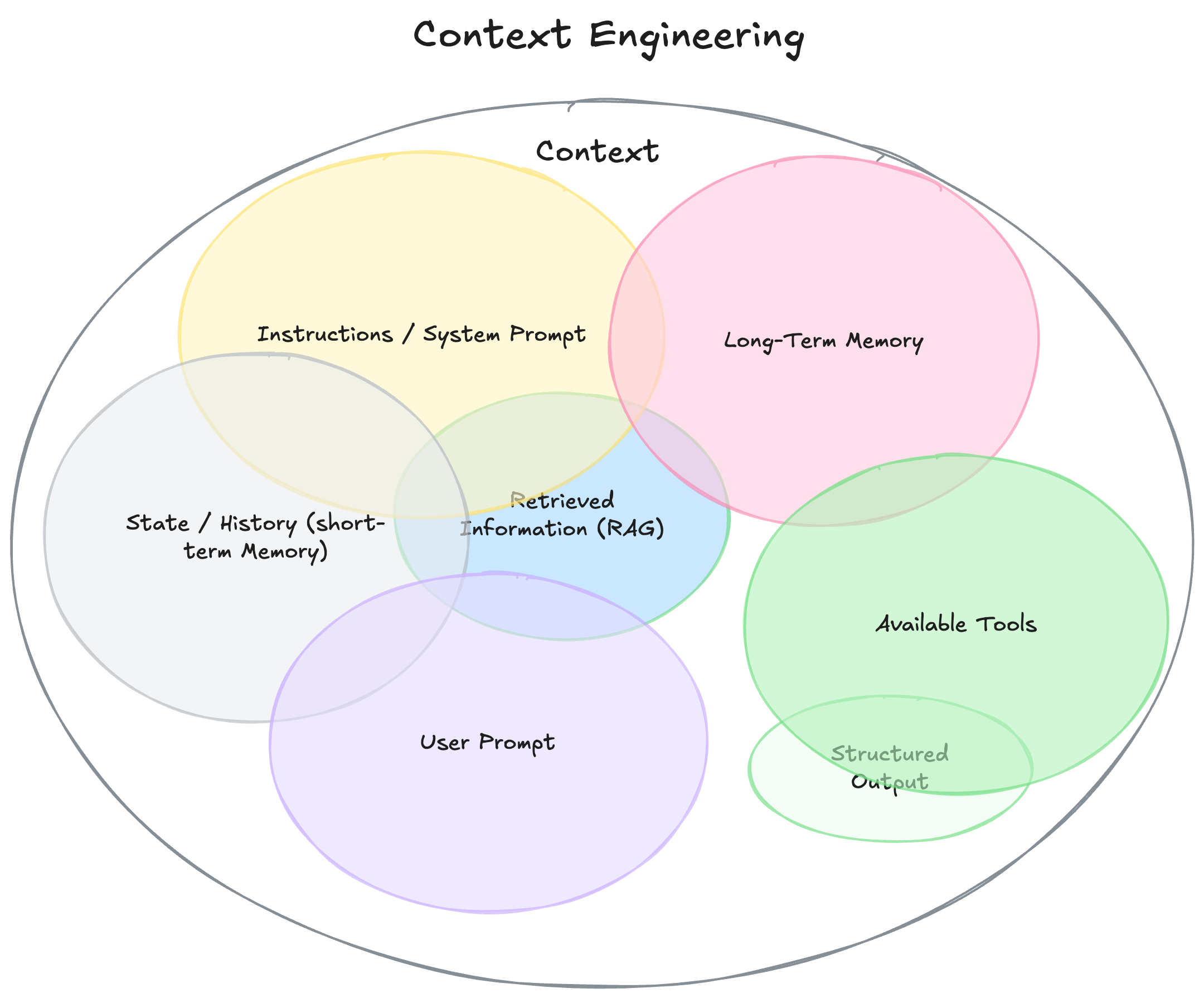
上下文组成要素(Photo by philschmid.de)
一个完整的上下文通常包含以下核心要素:
- 说明/系统提示:定义模型行为的初始说明集,包括示例、规则和行为指导。
- 用户提示:来自用户的即时任务或问题。
- 状态/历史(短期记忆):当前对话上下文,包括用户与模型的交互历史。
- 长期记忆:持久知识库,包含用户偏好、历史总结等。
- 检索信息(RAG):外部知识,如文档、数据库、API查询结果。
- 可用工具:模型可调用的所有函数或工具定义。
- 结构化输出:模型响应的格式定义,如JSON等。
在构建 LLM 应用程序时,我们需要管理哪些类型的上下文?上下文工程涵盖以下几种不同的上下文类型:
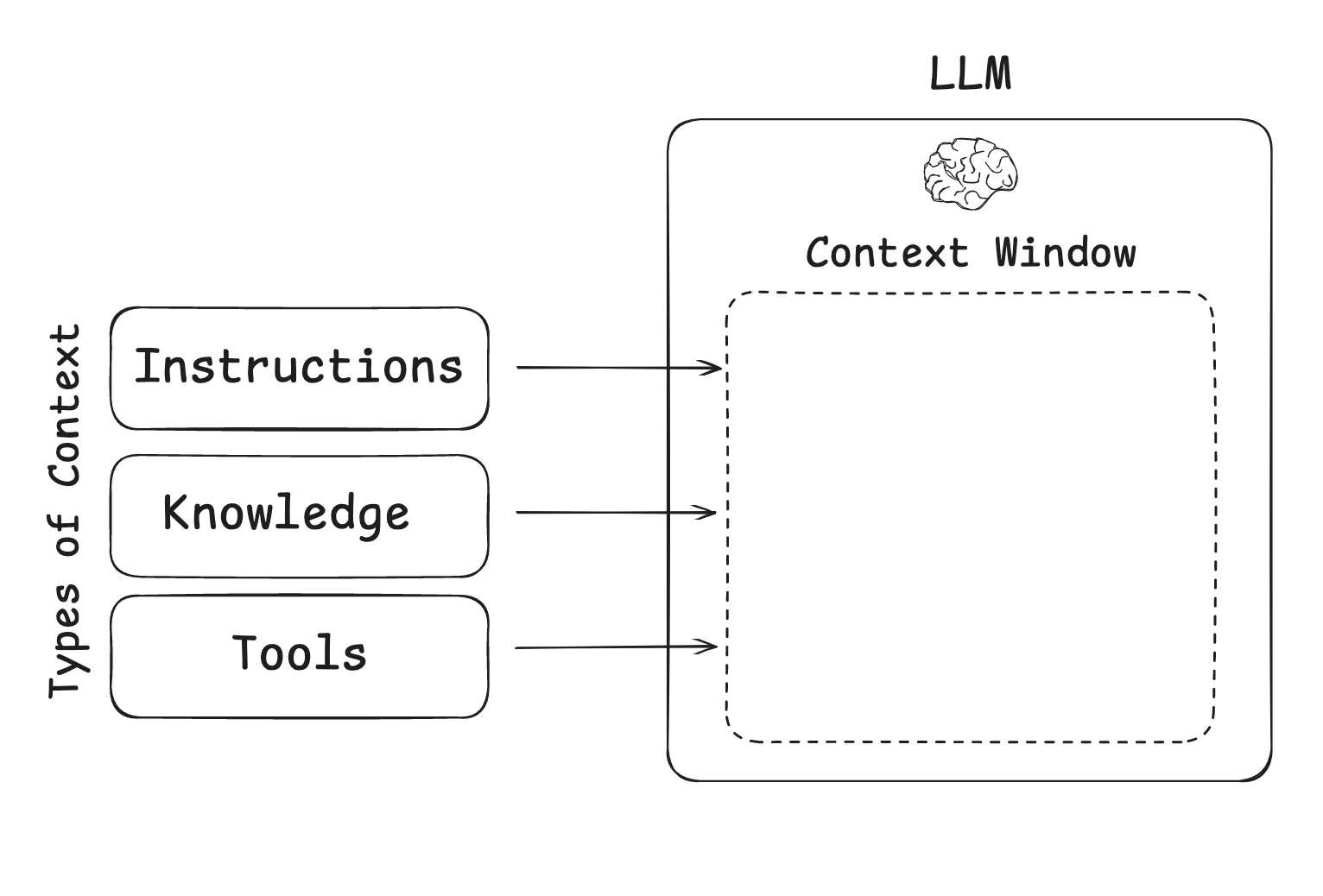
上下文类型(Photo by rlancemartin)
- 说明——提示、记忆、少量样本、工具描述等
- 知识——事实、记忆等
- 工具——工具调用的反馈
实际应用中需根据任务特性和资源限制合理组合、排序不同类型上下文,确保模型获取最相关、最有价值的信息。
3. 上下文工程的重要性与挑战
构建高效智能体的秘诀,与代码复杂性关系不大,而在于上下文的质量。上下文工程之所以重要,体现在:
- 提升模型能力:同一模型,不同上下文设计,能力表现可有巨大差异。
- 降低成本:精准提供必要信息,减少token消耗。
- 增强可靠性:充分背景信息可减少幻觉和错误。
- 实现个性化:通过记忆和上下文管理,实现跨会话的个性化体验。
- 扩展能力边界:通过工具和外部资源集成,突破模型原有能力限制。
上下文工程既是科学(需任务描述、示例、RAG、工具、状态、历史、压缩等),也是艺术(需理解LLM的"心理学",合理组织和权衡信息)。
4. 上下文工程的实践方法
4.1 实践方法
上下文包括消息列表之外的任何数据,这些数据可以影响代理行为或工具执行。这可以是
- 工具集成:为智能体配备必要工具,返回结构化、易于理解的信息。
- 记忆管理:短期记忆用摘要避免历史对话占满窗口,长期记忆存储用户偏好并可检索。
- 动态检索:根据用户查询动态获取、筛选、格式化最相关外部信息。
- 上下文格式化:精心设计提示结构、检索文档呈现、历史记录组织和结构化输出规范。
4.2. LangGraph框架中的上下文管理
LangGraph提供了强大的上下文管理能力。其上下文不仅包括消息列表,还包括影响智能体行为或工具执行的所有数据。
- 配置:运行开始时传递的数据,生命周期为每次运行。
- 状态:执行期间可更改的动态数据,生命周期为每次运行或会话。
- 长期记忆(存储):可在会话间共享的数据,生命周期为跨会话。
这些上下文类型可用于调整系统提示、为工具提供输入、跟踪会话事实等。
langchain 的 上下文代码示例
import os
from langchain_deepseek import ChatDeepSeek
from typing import List, Dict
from pydantic import SecretStr
# 定义CustomState,模拟多维上下文(如用户信息、历史消息等)
class CustomState:
def __init__(self, user_name: str, messages: List[Dict[str, str]] = []):
self.user_name = user_name
self.messages = messages # 消息历史,格式为 [{role: ..., content: ...}]
# prompt函数,动态生成systemprompt,实现个性化上下文注入
def prompt(state: CustomState) -> List[Dict[str, str]]:
user_name = state.user_name
system_msg = f"You are a helpful assistant. Address the user as {user_name}."
return [{"role": "system", "content": system_msg}] + state.messages
# 初始化DeepSeek聊天模型,支持上下文感知对话
llm = ChatDeepSeek(
model="deepseek-chat",
temperature=0.3,
api_key=SecretStr("type-your-api-key")
)
def main():
# 构造带有上下文的状态对象
state = CustomState(
user_name="John Smith",
messages=[{"role": "user", "content": "hi!"}]
)
# 生成带上下文的消息序列
messages = prompt(state)
# 调用LLM,输出上下文感知的回复
response = llm.invoke([(m["role"], m["content"]) for m in messages])
print(f"[DeepSeek] {response.content}")
if __name__ == "__main__":
main()
上述代码展示了如何通过自定义状态对象和动态prompt生成,实现上下文工程的基本落地。每一步注释均明确对应上下文工程的核心实践。
6. 结语
上下文工程标志着AI应用开发范式的重要转变。从"ChatGPT包装器"到复杂智能系统,核心在于如何在有限窗口中最大化信息价值、在正确时间提供正确信息,并设计高效的上下文管理架构。
构建强大可靠的AI智能体,不仅需要模型和提示,更需要精心设计的上下文工程。